
type
status
date
Apr 15, 2024 12:35 PM
slug
summary
category
tags
password
icon
Transformer(宏观结构)Encoder宏观结构Decoder宏观结构Transformer结构细节输入词向量位置编码(位置向量)EncoderSelf-Attention LayerMultihead Attention残差连接Decoder线性层和softmaxTransformer其他细节为什么 Decoder 需要做 Mask?为什么 Encoder 给予 Decoder 的是 K、V 矩阵?Transformer 的并行化相关面试题Transformer为何使用多头注意力机制?(为什么不使用一个头?)Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
Transformer(宏观结构)

- Transformer最初用来解决机器翻译任务,可以看作是seq2seq模型的一种。以机器翻译任务为例,先将Transformer看作一个黑盒,黑盒的输入是法语文本序列,输出是英语文本序列。

- 将上图中的中间部分“THE TRANSFORMER”拆开成seq2seq结构,得到下图:左边是编码器部分Encoders,右边是解码器部分Decoders。

- 再将上图中的Encoders和Decoders细节绘出得到下图。可以看到,Encoders由多层Encoder组成(原论文中使用的是6层Encoder)。同理,解码器Decoders也是由多层的Decoder组成(原论文中使用的是6层Decoder)。每层的Encoder网络结构是一样的,每层的Decoder网络结构也是一样的。不同层Encoder和Decoder网络结构不共享参数。

Encoder宏观结构

- Encoder由Self-Attention Layer和Feed Forward Neural Network(前馈神经网络,缩写为 FFNN)组成。
- 编码器的输入文本序列最开始需要经过embedding转换,得到每个单词的向量表示,其中是维度为的向量,然后所有向量经过一个Self-Attention神经网络层进行变换和信息交互得到,其中是维度为的向量。self-attention层处理一个词向量的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息(可以类比为:当翻译一个词的时候,不仅会只关注当前的词,也会关注这个词的上下文的其他词的信息)。Self-Attention层的输出会经过前馈神经网络得到新的,依旧是个维度为的向量。这些向量将被送入下一层encoder,继续相同的操作。
Decoder宏观结构

- Decoder由Self-Attention Layer、Encoder-Decoder Attention和Feed Forward Neural Network(前馈神经网络,缩写为 FFNN)组成。
Transformer结构细节
输入

词向量
- 首先会使用词嵌入算法(embedding algorithm),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 或者 维。但为了简化起见,这里使用维的词向量来进行讲解。
- 如下图所示,假设我们的输入文本是序列包含了个词,那么每个词可以通过词嵌入算法得到一个4维向量,于是整个输入被转化成为一个向量序列。
在实际应用中,通常会同时给模型输入多个句子,如果每个句子的长度不一样,我们会选择一个合适的长度,作为输入文本序列的最大长度:
- 如果一个句子达不到这个长度,那么就填充先填充一个特殊的“padding”词;
- 如果句子超出这个长度,则做截断。
最大序列长度是一个超参数,通常希望越大越好,但是更长的序列往往会占用更大的训练显存/内存,因此需要在模型训练时候视情况进行决定。
位置编码(位置向量)
- Transformer模型对每个输入的词向量都加上了一个位置向量。位置向量有助于确定每个单词的位置特征,或者句子中不同单词之间的距离特征。词向量加上位置向量背后的直觉是:将这些表示位置的向量添加到词向量中,得到的新向量,可以为模型提供更多有意义的信息,比如词的位置,词之间的距离等。
- 位置编码的要求:
- 每个时间步长(句子中的每一个单词)的唯一编码值,也就是一个,对应一个单词,对应一个编码。
- 不同长度的句子中两个时间步之间的距离一致。
- 编码结果的概括与句子的长度无关。
- 编码是确定性的
- 位置编码(Position Encoding)公式:
上面表达式中的代表词的位置,代表位置向量的维度,代表位置维位置向量第维。根据上述公式可知,第位置的维位置向量。
- 下图展示了一种位置向量在第4、5、6、7维度、不同位置的的数值大小。横坐标表示位置下标,纵坐标表示数值大小。

当然,上述公式不是唯一生成位置编码向量的方法。但这种方法的优点是:可以扩展到未知的序列长度。例如:当我们的模型需要翻译一个句子,而这个句子的长度大于训练集中所有句子的长度,这时,这种位置编码的方法也可以生成一样长的位置编码向量。
- 这里介绍一种使用二进制来进行位置编码的方法:例如,维度为 3 的 8 个位置的位置编码。

Encoder
融合位置信息的词向量进入self-attention层,self-attention的输出每个位置的向量再输入FFNN神经网络得到每个位置的新向量。

Self-Attention Layer
Self-Attention机制作用:可以使得模型不仅仅关注当前位置的词,还会关注句子中其他位置的相关的词,进而可以更好地理解当前位置的词。
- 什么是Self-Attention自注意力机制?
- 假设一句话包含两个单词:Thinking Machines。自注意力的一种理解是:Thinking-Thinking,Thinking-Machines,Machines-Thinking,Machines-Machines,共种,两两attention。
- 那么具体如何计算呢?假设Thinking、Machines这两个单词经过词向量算法得到向量是:
- 对以上的例子进行可视化:
- 对输入编码器的词向量进行线性变换得到:Query向量: ,Key向量: ,Value向量: 。这3个向量是词向量分别和3个参数矩阵相乘得到的,而这3个参数矩阵也是是模型要学习的参数。
- 计算Attention Score(注意力分数):Attention score是根据"Thinking" 对应的 Query 向量和其他位置的每个词的 Key 向量进行点积得到的。Thinking的第一个Attention Score就是和的内积,第二个分数就是和的点积。
- 把每个Attention Score(注意力分数)除以,是Key向量的维度。
- 把这些Attention Score(注意力分数)经过一个Softmax函数,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于1, 如下图所示。 这些分数决定了Thinking词向量,对其他所有位置的词向量分别有多少的注意力。
- 得到每个词向量的分数后,将分数分别与对应的Value向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的。
- 把第5步得到的Value向量相加,就得到了Self Attention在当前位置(这里的例子是第1个位置)对应的输出。


也可以除以其他数,除以一个数是为了在反向传播时,求梯度时更加稳定。


Multihead Attention
- Transformer 的论文通过增加多头注意力机制(一组注意力称为一个 attention head),进一步完善了Self-Attention。这种机制从如下两个方面增强了attention层的能力:
- 它扩展了模型关注不同位置的能力,每个head可以学习到不同的东西。在上面的例子中,第一个位置的输出包含了句子中其他每个位置的很小一部分信息,但仅仅是单个向量,所以可能仅由第1个位置的信息主导了。而当我们翻译句子:
The animal didn’t cross the street because it was too tired时,我们不仅希望模型关注到"it"本身,还希望模型关注到"The"和"anima",甚至关注到"tired"。这时,多头注意力机制会有帮助。 - 多头注意力机制赋予attention层多个“子表示空间”,而不仅仅是单一表示。下面我们会看到,多头注意力机制会有多组 的权重矩阵(在 Transformer 的论文中,使用了 8 组注意力),因此可以将变换到更多种子空间进行表示。接下来我们也使用8组注意力头)。每一组注意力的权重矩阵都是随机初始化的,但经过训练之后,每一组注意力的权重$W^Q, W^K W^V$ 可以把输入的向量映射到一个对应的“子表示空间”。
- 在多头注意力机制中,我们为每组注意力设定单独的 参数矩阵。将输入和每组注意力的 相乘,得到8组 矩阵。

- 接着,我们把每组 计算得到每组的 矩阵,就得到8个Z矩阵。

- 由于前馈神经网络层接收的是 1 个矩阵(其中每行的向量表示一个词),而不是 8 个矩阵,所以我们直接把8个子矩阵拼接起来得到一个大的矩阵,然后和另一个权重矩阵(称为 additional weight matrix,附加权重矩阵)相乘做一次变换,映射到前馈神经网络层所需要的维度,得到最终的矩阵Z,这个矩阵包含了所有 attention heads(注意力头) 的信息。这个矩阵会输入到FFNN (Feed Forward Neural Network)层。

残差连接
到目前为止,我们计算得到了self-attention的输出向量。而单层Encoder里后续还有两个重要的操作:残差连接、标准化。Encoder的每个子层(Self Attention 层和 FFNN)都有一个残差连接和层标准化(Layer Normalization),如下图所示。

- 将 Self-Attention Layer的层标准化(Layer Normalization)和涉及的向量计算细节都进行可视化,如图所示。

- Encoder和Decoder的子层里面都有层标准化(Layer Normalization)。假设一个 Transformer 是由 2 层编码器和两层解码器组成的,将全部内部细节展示起来如下图所示。

Decoder
- Encoders一般有多层,第一个Encoder的输入是一个序列文本,最后一个Encoder输出是一组序列向量,这组序列向量会作为Decoder的K、V输入,其中K=V=Decoder输出的序列向量表示。这些注意力向量将会输入到每个Decoder的Encoder-Decoder Attention层,这有助于解码器把注意力集中到输入序列的合适位置,如下图所示。
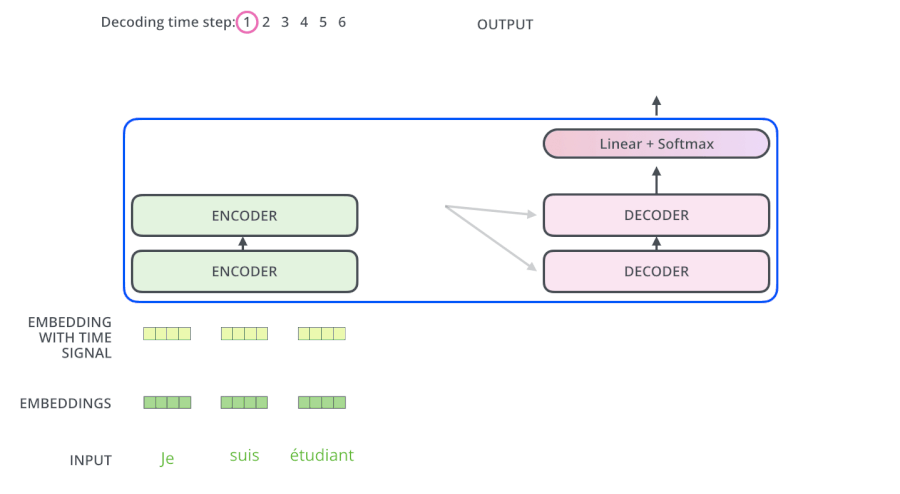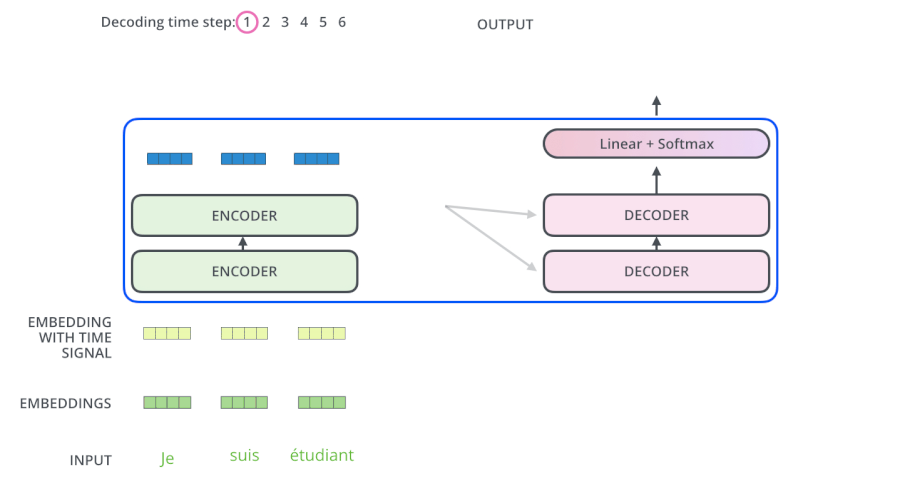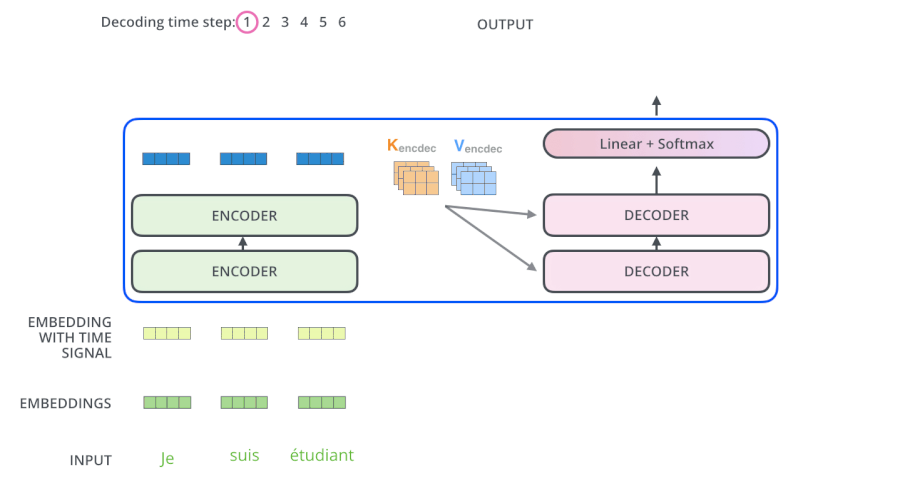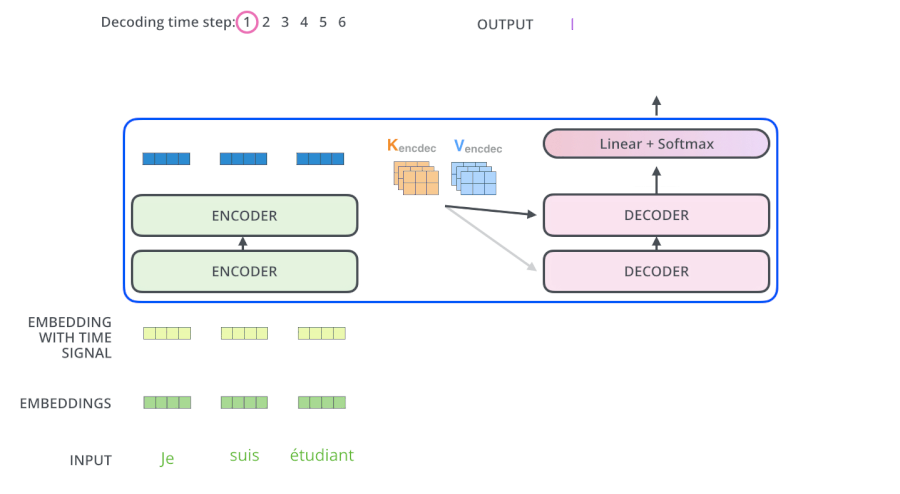

- 解码(decoding )阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译),解码器当前时间步的输出又重新作为输入Q和编码器的输出K、V共同作为下一个时间步解码器的输入。然后重复这个过程,直到输出一个结束符。如下图所示。
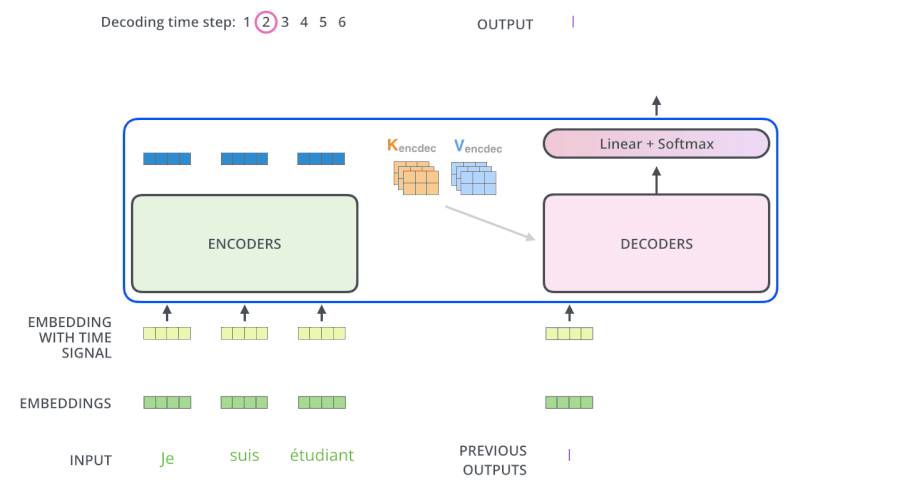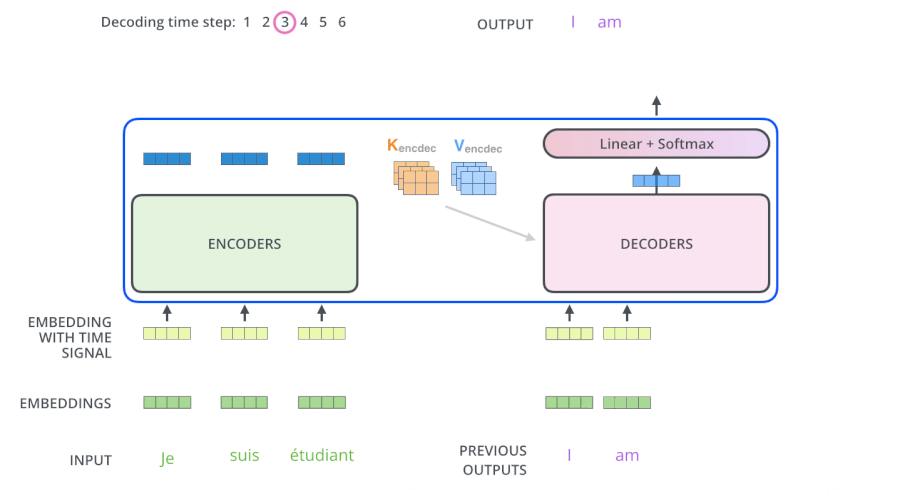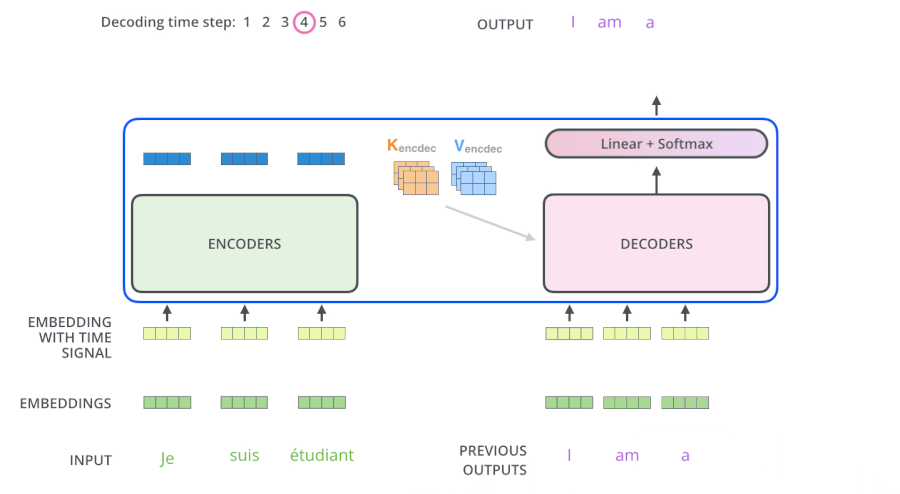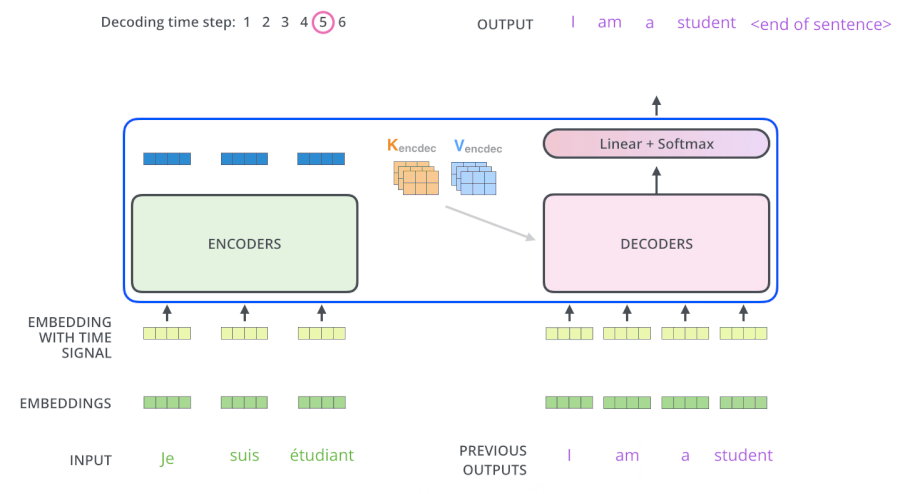
- Decoder 中的 Self Attention 层,和 Encoder 中的 Self Attention 层的区别:
- 在Decoder里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置(将attention score设置成-inf)。
- 解码器 Attention层是使用前一层的输出来构造 Query 矩阵,而Key矩阵和 Value矩阵来自于Encoder最终的输出。
线性层和softmax
- Decoder 最终的输出是一个向量,其中每个元素是浮点数。我们怎么把这个向量转换为单词呢?这是线性层和softmax完成的。
- 线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更大的向量,这个向量称为 logits 向量:假设我们的模型有 10000 个英语单词(模型的输出词汇表),此 logits 向量便会有 10000 个数字,每个数表示一个单词的分数。
- 然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。

Transformer其他细节
为什么 Decoder 需要做 Mask?
- 训练阶段:我们知道 “je suis etudiant” 的翻译结果为 “I am a student”,我们把 “I am a student” 的 Embedding 输入到 Decoders 里面,翻译第一个词 “I” 时
- 如果对 “I am a student” attention 计算不做 mask,“am,a,student” 对 “I” 的翻译将会有一定的贡献
- 如果对 “I am a student” attention 计算做 mask,“am,a,student” 对 “I” 的翻译将没有贡献
- 测试阶段:我们不知道 “我爱中国” 的翻译结果为 “I love China”,我们只能随机初始化一个 Embedding 输入到 Decoders 里面,翻译第一个词 “I” 时:
- 无论是否做 mask,“love,China” 对 “I” 的翻译都不会产生贡献
- 但是翻译了第一个词 “I” 后,随机初始化的 Embedding 有了 “I” 的 Embedding,也就是说在翻译第二词 “love” 的时候,“I” 的 Embedding 将有一定的贡献,但是 “China” 对 “love” 的翻译毫无贡献,随之翻译的进行,已经翻译的结果将会对下一个要翻译的词都会有一定的贡献,这就和做了 mask 的训练阶段做到了一种匹配。
总结下就是:Decoder 做 Mask,是为了让训练阶段和测试阶段行为一致,不会出现间隙,避免过拟合!
为什么 Encoder 给予 Decoder 的是 K、V 矩阵?
我们在讲解 Attention 机制中曾提到,Query 的目的是借助它从一堆信息中找到重要的信息。
现在 Encoder 提供了 矩阵,Decoder 提供了 矩阵,通过 “我爱中国” 翻译为 “I love China” 这句话详细解释下。
当我们翻译 “I” 的时候,由于 Decoder 提供了 矩阵,通过与 矩阵的计算,它可以在 “我爱中国” 这四个字中找到对 “I” 翻译最有用的单词是哪几个,并以此为依据翻译出 “I” 这个单词,这就很好的体现了注意力机制想要达到的目的,把焦点放在对自己而言更为重要的信息上。
- 其实上述说的就是 Attention 里的 soft attention机制,解决了曾经的 Encoder-Decoder 框架的一个问题,在这里不多做叙述,有兴趣的可以参考网上的一些资料。
- 早期的 Encoder-Decoder 框架中的 Encoder 通过 LSTM 提取出源句(Source) “我爱中国” 的特征信息 C,然后 Decoder 做翻译的时候,目标句(Target)“I love China” 中的任何一个单词的翻译都来源于相同特征信息 C,这种做法是极其不合理的,例如翻译 “I” 时应该着眼于 “我”,翻译 “China” 应该着眼于 “中国”,而早期的这种做法并没有体现出,然而 Transformer 却通过 Attention 的做法解决了这个问题。
Transformer 的并行化
- decoder 没有并行化,6 个encoder 之间也没有并行化,encoder 内部的两个子模块也没有并行化,但是 encoder 内部的两个子模块自身是可以并行化的【和前一句话并不矛盾,这句话的意思是encoder 内部的两个子模块之间没有并行化,但是encoder 内部的两个子模块自身是可以并行化的,例如在计算的时候就可以并行化!】
相关面试题
Transformer为何使用多头注意力机制?(为什么不使用一个头?)
- 多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。
Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)
- 使用Q/K/V不相同可以保证在不同空间进行投影,增强了表达能力,提高了泛化能力。
Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
- 牛客面试:
- 作者:Frank
- 链接:https://blog.franksteven.me//article/transformer
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。